Global Sportswear Brand
Designing Trust in Event Data
Making analytics definitions easier to understand across business, product, engineering, and marketing
At stake
When analytics implementation outruns shared understanding
Retail corporations like Nike invest heavily in capturing consumer behavior at scale. But data only creates value when the people who depend on it can understand and trust it.
During Nike's analytics transition from JSON-based event schemas toward Protobuf definitions, a technical improvement created an organizational problem. Protobufs offer stronger governance and scale, but they replaced human-readable events like eventName = "Product Clicked" with nested structures like action_nm = core.commerce.v1.cart_modified, difficult to expand and harder for most data consumers to interpret without help.
That help typically meant going through the Clickstream team, specialists who manage the schema tables and understood their structure. They are incredibly intelligent and helpful people, but every migration question, every mapping conversation, every “how “does this event fire and what data is captured on it” routed through their small team.
The result was a migration happening faster than trust could form. Teams were being asked to move their reporting dashboards to a new data structure they didn't fully understand, with no clear way to see what existed, how old events mapped to new ones, or whether the data they were migrating to was actually equivalent to what they were leaving behind.
My team owned the data infrastructure end to end. During a holiday deployment freeze, when no production code could ship, a group of mostly back-end engineers and I turned the downtime into an opportunity and built the information layer that data consumers had been missing.
Scope & constraints
Role, migration context, and who depended on the system
I led product design and analytics alignment for an internal data product within Nike Halfpipe, the clickstream data engineering team, from stakeholder interviews and wireframes through prototyping and launch behind Okta on Nike's intranet.
Stakeholders included engineering, markteting and ad-tech, product and business teams, and all data consumers including Adobe Experience Platform teams where event mapping and parity was of great concern. But the scope of who depended on this system was much larger than that list suggests.
This is the consumer behavior data that Nike's entire digital business runs on. Every product decision, every marketing investment, every merchandising call that depends on how customers behave online traces back to this clickstream. When data consumers can't easily understand the events they're working with, when the only path to an answer is opening Protobuf definition files in GitHub, analysis slows down, reporting gaps open up, and the business leaders who depend on that reporting are making decisions on data they can't fully trust. At the scale Nike operates, that's a very expensive compounding problem.
System snapshot
From user action to analytics use case
The system chains user behavior to downstream measurement. The internal explorer sits between machine-readable infrastructure and the people who need to use it.
- User interaction → clickstream event → event definition (actions, event types, digital surfaces) → pipeline / table / receiver → analytics use case.
- 269 unique actions, 6 event types, and 5 digital surfaces need a shared taxonomy — not filenames or nested proto files as the entry point.
- Protobuf definitions govern what ships; JSON was the mental model many teams still used to reason about behavior.
- Downstream consumers include Adobe Analytics / AEP mapping, Databricks Silver tables, and internal QA — each with different questions about parity and meaning.
- The product is a translation layer: make schemas explorable so business, product, engineering, and analytics can answer “what data exists?” without opening GitHub for every question.
What I optimized for
Principles for a trustworthy translation layer
- 1. Make schemas explorable, not buried — search, browse, and read definitions in one product surface.
- 2. Translate machine structure into human understanding — inheritance, global fields, and action payloads read as behavior, not only syntax.
- 3. Preserve governance without losing usability — Protobuf stays authoritative; the UI carries the comprehension tax.
- 4. Support trust during migration — parity, metadata, and downstream context visible while JSON and Protobuf definitions coexist.
- 5. Help teams answer “what data exists?” without engineering support for routine schema questions.
Decision 1
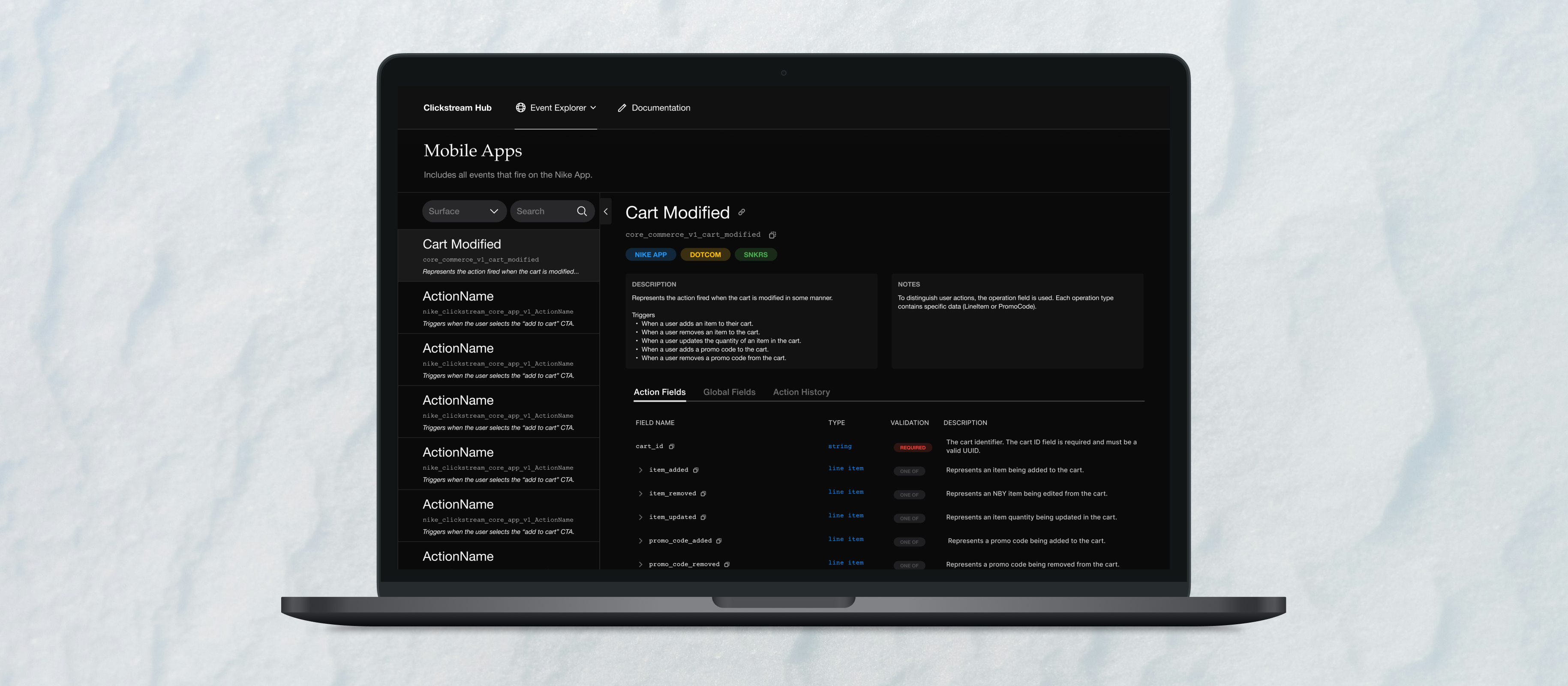
Turn Protobuf definitions into an explorable product surface
What changed: Schema details became searchable and readable in a catalog organized by actions and digital surfaces — not as a static export or repo tour.
Why it mattered: Protobuf is precise for systems; without an explorable layer, non-engineering stakeholders route around the source of truth and trust erodes.
What constrained it: The UI had to stay credible as contracts evolved — exploration could not fall behind production definitions.
Decision 2
Design around the JSON → Protobuf comprehension gap
What changed: The experience sequences context the way cross-functional teams build confidence — global structure and shared fields before action-specific payloads — with narrative documentation beside generated Protobuf reference.
Why it mattered: JSON was easier to scan; Protobuf was easier to govern. The product had to carry both truths: respect the governed contract while making nested structure legible.
What constrained it: Automated documentation had to track schema changes; the UI and generated docs reinforce each other instead of drifting apart.
JSON → Protobuf gap — govern at the schema layer; translate at the product layer.
Decision 3
Connect event definitions to real analytics use cases
What changed: Event-level views foreground context, event type, and digital surface before action-scoped fields and history — so conversations tie back to measurement and downstream receivers.
Why it mattered: Teams need to connect “cart modified” (or any action) to what fires, where, and what Adobe or warehouse consumers should expect — not only field names.
What constrained it: Precision still matters for QA and analytics; the layout could not oversimplify inheritance or action-level differences.
Decision 4
Reduce dependency on scattered docs and engineering interpretation
What changed: Action history, field-level views, and in-product documentation answer routine questions in one place — who changed what, what applies here, and how this slice differs from inherited layers.
Why it mattered: When definitions live in GitHub, Slack, and static exports, the same schema questions reopen in every migration and mapping review.
What constrained it: Complex edge cases still need engineering partnership; the product targets the high-volume “basic understanding” work that was slowing everyone down.
Decision 5
Build a durable internal data product on real infrastructure
What changed: The experience ships as an internal SvelteKit app with a Go backend, Okta OAuth 2.0, and deployment on ECS Fargate — a Go reverse proxy serving a Node.js SSR frontend so the surface behaves as one product in production. GitHub Actions keeps Protobuf documentation current as schemas change.
Why it mattered: Comprehension tools fail when access, freshness, or deployment are afterthoughts; infrastructure choices support adoption, not just a prototype.
What constrained it: Internal auth, single-container ops, and CI/CD for generated docs were requirements from the start — design and engineering shared ownership of how definitions reach users.
Results
What changed
- ↑ Created a central interface for exploring clickstream definitions across 269 unique actions, 6 event types, and 5 digital surfaces
- ↑ Made Protobuf-based event definitions more accessible to analytics, product, business, and engineering stakeholders
- ↓ Reduced reliance on GitHub or engineering interpretation for basic schema understanding
- ↑ Supported trust and adoption during the move from legacy JSON-based analytics toward a more governed clickstream ecosystem
- ↑ Helped bridge Adobe Analytics / AEP mapping conversations with modern clickstream definitions
- ↑ Established a foundation for future internal data product patterns
The work treats event comprehension as a product problem — not only a documentation problem. Teams spend less time decoding structure and more time aligning on what instrumentation captures and whether downstream analytics can rely on it.
Next
What I'd push further
Next pass: lineage views from event definition → pipeline / table → dashboard or report, so downstream meaning is one click from the schema — not a separate investigation.
Health or confidence signals from SignalFx and pipeline observability could sit beside definitions, surfacing drift or volume issues where teams already validate meaning.
Clearer ownership, usage examples, and connections from schema fields to reporting and business language would close the gap between “what the proto says” and “what we decided to measure.”
